
3.02 Z-scores
Ideas
Z-scores
To directly compare multiple normally distributed data sets, we need a common unit of measurement. In statistics involving the normal distribution, we use the number of standard deviations away from the mean as a standardized unit of measurement called a z-score.
Exploration
Imagine two students took different standardized tests. Student A scored 1200 on the SAT, where the mean was 1050 and the standard deviation was 200. Student B scored 25 on the ACT, where the mean was 21 and the standard deviation was 5.
How far above the mean did Student A score on the SAT?
How far above the mean did Student B score on the ACT?
Based only on the distance above the mean, who seems to have performed better?
Now consider the spread (standard deviation) of the scores. How many standard deviations above the mean was Student A's score? How many standard deviations above the mean was Student B's score?
Thinking about performance relative to others taking the same test (i.e., considering standard deviations), who performed better? Why is just looking at the raw score difference from the mean potentially misleading when comparing scores from different distributions?
We can use z-scores along with the standard normal distribution to compare values from different sets of data.

For example, a data set that is normally distributed with a mean of 1010 and a standard deviation of 20 can be standardized with z-scores. This would allow us to compare other sets of similar data with a different mean and standard deviation.

To find the z-score of a data value, we must know the mean and standard deviation. If we know those values, we can use the following formula to find the equivalent z-score.
A positive z-score indicates the data value was above the mean.
A z-score of 0 indicates the data value was equal to the mean.
A negative z-score indicates the data value was below the mean.
The larger the magnitude of the z-score, the further the score is from the mean.
The empirical rule can also be used to estimate the percentage of data within 1, 2, and 3 standard deviations on the mean in the standard normal distribution.

Examples
Example 1
Brock is applying to different colleges across America and needs to decide if he should emphasize his SAT score, ACT score, or both. The test scores for both the SAT and ACT are normally distributed. The data is summarized in the table.
| Brock's score | Mean | Standard Deviation | |
|---|---|---|---|
| SAT | 1450 | 1051 | 211 |
| ACT | 30 | 20.8 | 5.7 |
Calculate and interpret the z-score for Brock's SAT score.
Calculate and interpret the z-score for Brock's ACT score.
Determine which test Brock did better on relative to all other SAT and ACT test takers.
Example 2
Three sprinters are training for a national competition. The data collected on each of their running times (in seconds) is approximately normal. Information for their mean, standard deviation, a practice 400\text{ m} sprint and its corresponding z-score are in the table.
| \mu | \sigma | z\text{-score} | \text{Practice time} | |
|---|---|---|---|---|
| Lina | 65 | 3 | -1.27 | |
| Aurelia | 62 | 0.85 | 65.4 | |
| Mariana | 2 | -0.5 | 59.5 |
Find the 400\text{ m} sprint time Lina ran during practice.
Find the standard deviation of Aurelia's times.
Find the average 400\text{ m} sprint time for Mariana.
Example 3
An extreme amusement park ride only allows riders over 60 inches tall to ride. Colette was not allowed to ride because she did not meet the height requirement, but her younger brother Gavin was able to ride because he was taller than the height requirement. This led her to ask the question, "How do the heights of men compare to the heights of women?"
Describe a method Colette can use to collect data.
The data Colette collected on the heights of men and women is in the table.
| Female heights | Male heights |
|---|---|
| 66, 61, 62, 64, 60,\\62, 64, 63, 58, 64,\\60, 68, 62, 59, 64,\\60, 64, 66, 62, 62 | 71, 69, 71, 66, 69,\\77, 74, 72, 75, 71,\\68, 72, 70, 64, 73,\\68, 66, 70, 67, 73 |
Use technology to create a smooth curve to model each distribution and describe the shape of each curve.
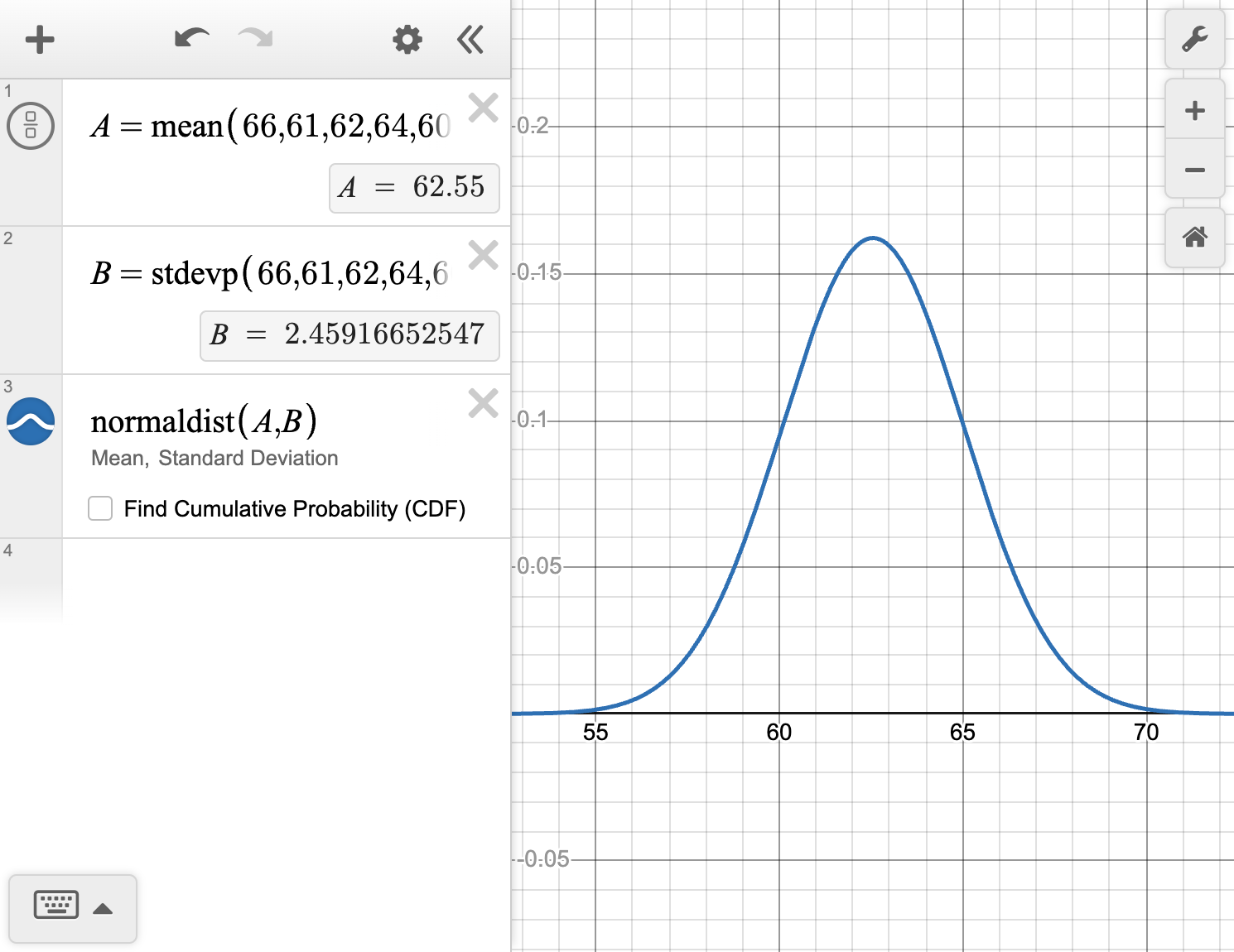
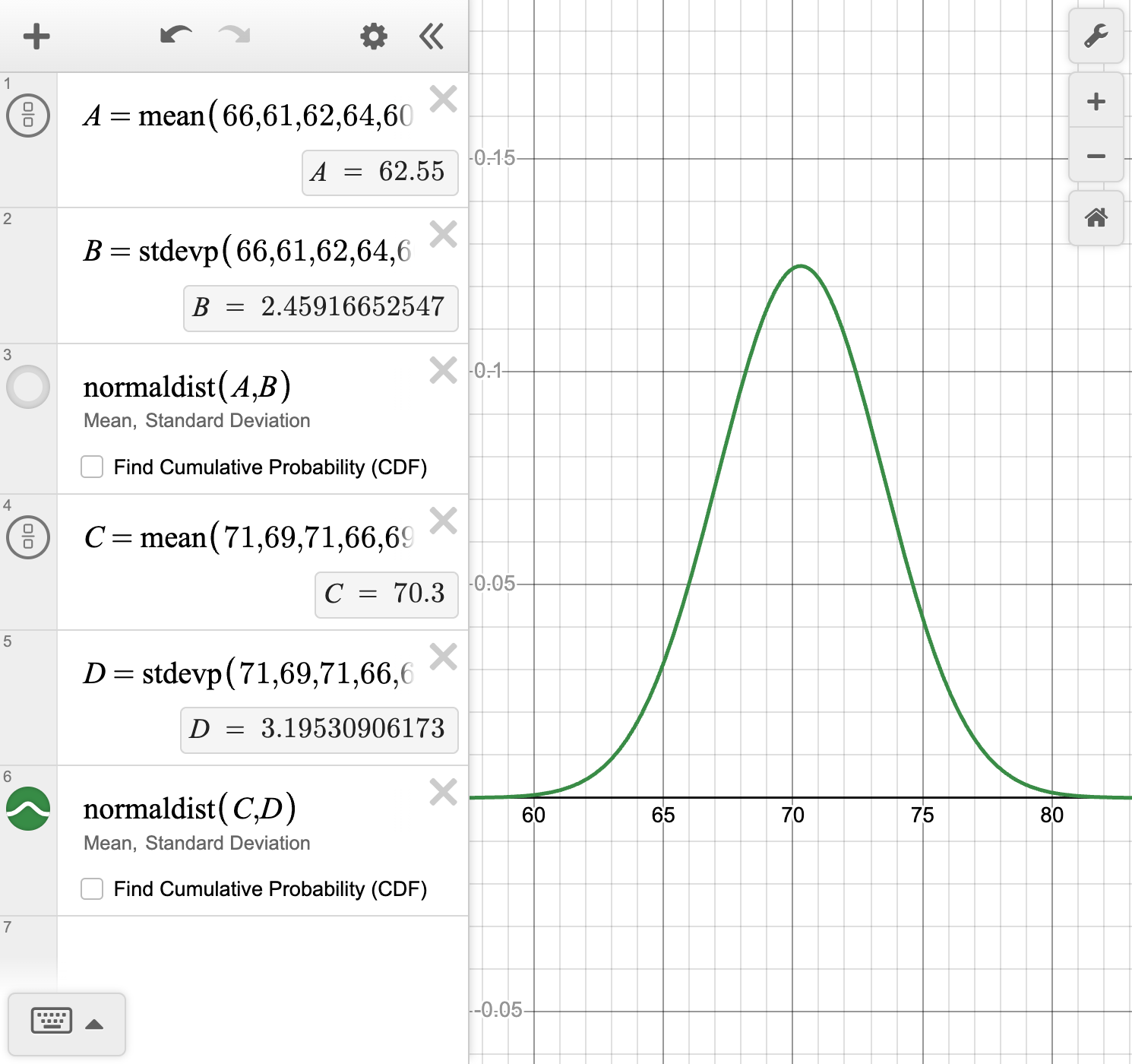
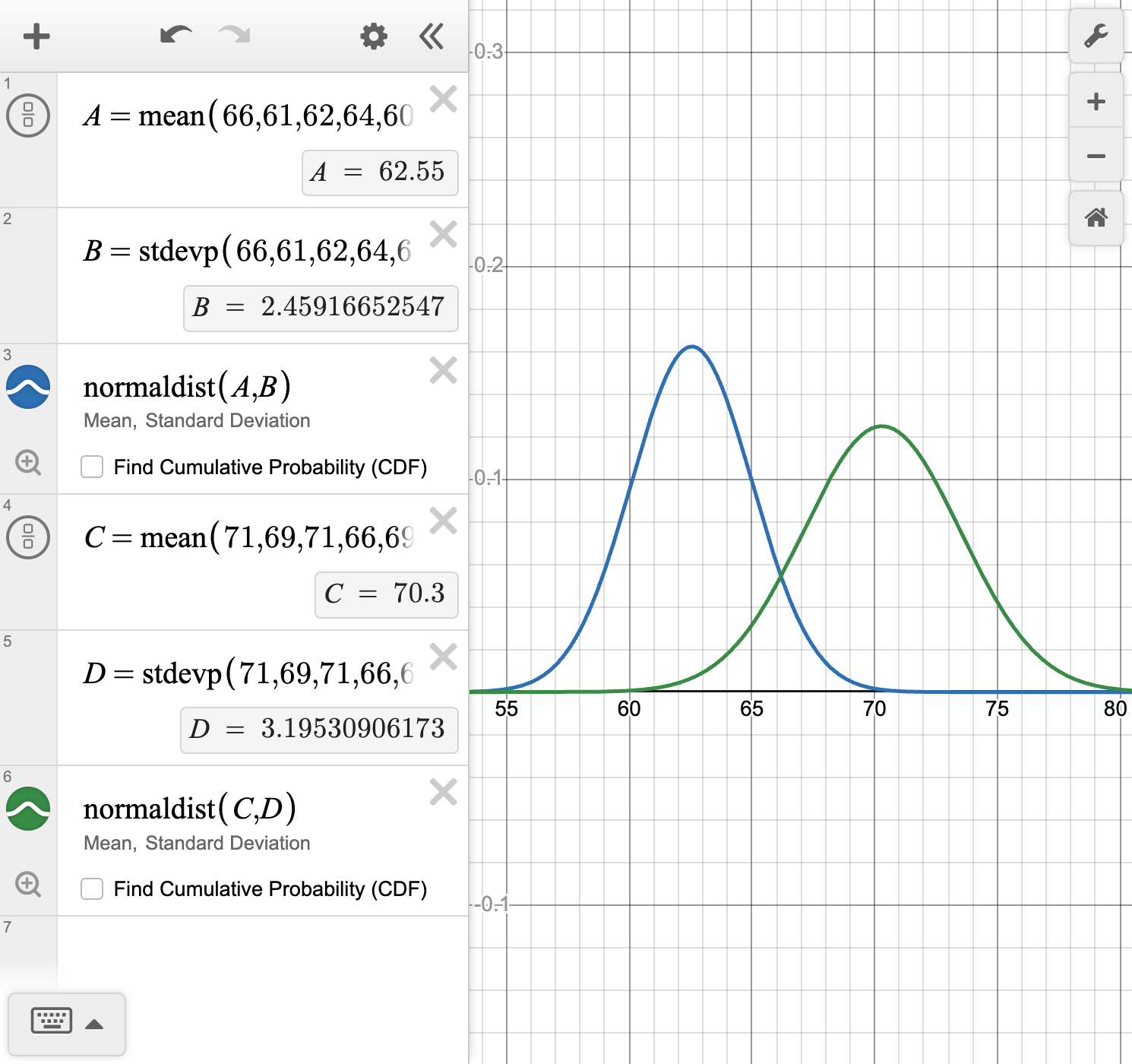
Answer the statistical question that Colette formulated.
Since both data sets are normally distributed, Colette wanted to further investigate men's and women's heights relative to the height requirement for the ride. Her new statistical question is, "How does the percentage of male riders who can ride this ride compare to the percentage of female riders who can ride?"
Find and interpret the z-scores for the 60-inch height requirement relative to the average American female heights and average American male heights.

Compare the percentage of male riders who can ride this ride to the percentage of female riders who can ride.

Data that is normally distributed can be normalized using z-scores. This allows us to compare data sets that have different means and standard deviations.
To find the z-score of a data value, we must know the mean and standard deviation. If we know those values, we can use the following formula to find the equivalent z-score.
Remember that a positive z-score means the data value is above the mean, a negative z-score means it's below the mean, and a z-score of 0 means it's equal to the mean. The larger the absolute value of the z-score, the further the data value is from the mean.